Consider a vector  where
where 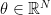 . It is often claimed that this distribution is “very close”, in the limit of large
. It is often claimed that this distribution is “very close”, in the limit of large  , to that of the uniform measure on the sphere
, to that of the uniform measure on the sphere  of unit radius. This is, in fact, not hard to see (informally) using a Chernoff bound argument. Firstly, let
of unit radius. This is, in fact, not hard to see (informally) using a Chernoff bound argument. Firstly, let 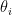 denote the
denote the  entry of
entry of  . More precisely, the Chernoff argument yields the following inequalities:
. More precisely, the Chernoff argument yields the following inequalities:
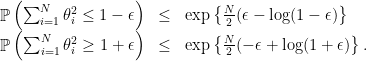
The way to obtain this is pretty standard. For instance the first inequality can be obtained as:
![\displaystyle \begin{array}{rcl} \mathop{\mathbb P}\left(\sum_{i=1}^N\theta_i^2 \le 1-\epsilon\right)&=&\mathop{\mathbb P}\left[\exp(-\lambda \sum_{i=1}^N\theta_i^2) \ge \exp(-\lambda(1-\epsilon)) \right]\\ &\le& \mathop{\mathbb E}\left[ \exp(-\lambda\sum_{i=1}^N \theta_i^2) \right]\exp(\lambda(1-\epsilon)), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%09%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%28%5Csum_%7Bi%3D1%7D%5EN%5Ctheta_i%5E2+%5Cle+1-%5Cepsilon%5Cright%29%26%3D%26%5Cmathop%7B%5Cmathbb+P%7D%5Cleft%5B%5Cexp%28-%5Clambda+%5Csum_%7Bi%3D1%7D%5EN%5Ctheta_i%5E2%29+%5Cge+%5Cexp%28-%5Clambda%281-%5Cepsilon%29%29+%5Cright%5D%5C%5C+%09%26%5Cle%26+%5Cmathop%7B%5Cmathbb+E%7D%5Cleft%5B+%5Cexp%28-%5Clambda%5Csum_%7Bi%3D1%7D%5EN+%5Ctheta_i%5E2%29+%5Cright%5D%5Cexp%28%5Clambda%281-%5Cepsilon%29%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
where 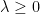 and the inequality is by Markov. Optimizing over
and the inequality is by Markov. Optimizing over  yields the result. This tells us that
yields the result. This tells us that 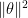 concentrates around the expected value of 1 at least to the extent of
concentrates around the expected value of 1 at least to the extent of 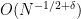 for a small constant
for a small constant  . In fact one can do better than this using an exact large deviations calculation, which I will probably leave to another post.
. In fact one can do better than this using an exact large deviations calculation, which I will probably leave to another post.
Thus for large dimensions , the probability mass of the distribution 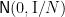 is concentrated in a shell of thickness
is concentrated in a shell of thickness 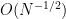 and mean radius 1, which intuitively, looks very much like
and mean radius 1, which intuitively, looks very much like  . The question that interested me is how we can prove the converse: assuming
. The question that interested me is how we can prove the converse: assuming 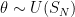 where
where 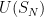 denotes the spherical measure on do the marginals of each entry, say
denotes the spherical measure on do the marginals of each entry, say  look Gaussian? More precisely, let
look Gaussian? More precisely, let 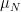 denote the measure of
denote the measure of 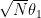 on
on  . Then, does converge weakly to
. Then, does converge weakly to  ? This is, in fact, true and is an old result due to Borel in his (book/treatise) “Introduction géometrique à quelques théorie physiques”. I will sketch a simple argument via characteristic functions.
? This is, in fact, true and is an old result due to Borel in his (book/treatise) “Introduction géometrique à quelques théorie physiques”. I will sketch a simple argument via characteristic functions.
The function 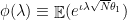 is the characteristic function of
is the characteristic function of  , where
, where  . We can compute this integral explicitly. The formula for the “area” of an -dimensional spherical cap as given (here) is:
. We can compute this integral explicitly. The formula for the “area” of an -dimensional spherical cap as given (here) is:

where  is the surface area of ,
is the surface area of ,  is the depth and
is the depth and 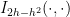 is the normalized incomplete beta function. Differentiating this, dividing by and noting that
is the normalized incomplete beta function. Differentiating this, dividing by and noting that 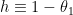 , we can compute the characteristic function as the following integral:
, we can compute the characteristic function as the following integral:

where 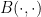 is the beta function. To do the above, we have to take care of a few sign conventions, which I have omitted. Now,
is the beta function. To do the above, we have to take care of a few sign conventions, which I have omitted. Now, 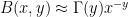 for fixed
for fixed  and large
and large  by Stirling’s approximation. With this and a change of variables
by Stirling’s approximation. With this and a change of variables  , we obtain:
, we obtain:
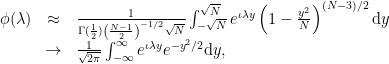
by dominated convergence. The last limit is precisely what we require, namely the characteristic function 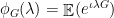 where
where  . The rest follows from Lévy’s continuity theorem.
. The rest follows from Lévy’s continuity theorem.
There are significant improvements to this result. Diaconis and Freedman prove that this holds for all low-dimensional marginals, even in the sense of variation distance. More precisely, let  denote the restriction of to the first
denote the restriction of to the first  entries. They give a sharp bound on the variation distance between the law of
entries. They give a sharp bound on the variation distance between the law of  and
and  . Interesting generalizations include this result by D’Aristotile, Diaconis and Newman which says that
. Interesting generalizations include this result by D’Aristotile, Diaconis and Newman which says that 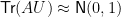 when
when  is a orthogonal matrix of size
is a orthogonal matrix of size  chosen uniformly at random, and
chosen uniformly at random, and 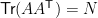 , and others which state that even a “small” submatrix of behaves as though its entries were iid standard normals.
, and others which state that even a “small” submatrix of behaves as though its entries were iid standard normals.
I am sure I have barely scratched the surface here, but it is clear that many (and sometimes intuitively plausible) approximations of this kind are actually fairly accurate even rigorously.
UPDATE (04/05/13): Thanks to Jiantao Jiao for some corrections above.
This entry was posted on February 5, 2013 at 2:44 PM and is filed under Uncategorized. You can follow any responses to this entry through the RSS 2.0 feed.
You can leave a response, or trackback from your own site.

Leave a comment